前言
字符串的匹配在任何系统中都是最流行的功能,许多算法可以完成这个任务,KMP是最常用的算法之一。它的名字跟功能并没有任何关联,仅仅是以三个发明者姓名首字母的缩写(Knuth-Morris-Pratt),起头的那个K就是著名科学家Donald Knuth。KMP是我刷算法遇到的第一块难啃的骨头,这完全不是能不能想到的问题,而是完全看不懂,学到最后不得不佩服发明者的脑洞之大。网络上已有很多能够详细分析该算法的文章,但我一直看的还是云里雾里,最终决定花些时间写一个更加通俗易懂的版本(至少对我是如此),其中些许可能与众不同的地方大多已做说明,希望能对大家有所启发。
基本定义1
字符串
字符串S是将n个字符顺次排列形成的序列,其中n称为S的长度,S的第i个字符表示为S[i]。(在有的地方,也会用S[i-1]表示第i个字符。)
子串
字符串S的子串S[i:j],(i<j)表示S串中从i到j这一段顺次排列的字符串。
后缀
后缀:指从某个位置i开始到整个串末尾结束的一个特殊子串。字符串S从i开头的后缀表示为Suffix(S,i) 。
真后缀:指除了S本身的其它后缀。
示例:字符串abcabcd的所有后缀为{d, cd, bcd, abcd, cabcd, bcabcd, abcabcd},而它的真后缀为{d, cd, bcd, abcd, cabcd, bcabcd}。
前缀
前缀:指从串首开始到某个位置i结束的一个特殊子串。字符串S到i结束的前缀表示为Prefix(S,i) 。
真前缀:指除了S本身的其它前缀。
示例:字符串abcabcd的所有前缀为{a, ab, abc, abca, abcab, abcabc, abcabcd},而它的真前缀为{a, ab, abc, abca, abcab, abcabc}。
KMP算法
假设需要匹配的主串为:txt="BBC ABCDAB ABCDABCDABDE",匹配的模式串为:pat="ABCDABD",下标索引从0开始。

常规字符串匹配算法
很容易想到的是暴力匹配算法,我们从主串txt的第一个字符开始检查其是否与模式串pat的第一个字符匹配2:

- 首先,主串
BBC ABCDAB ABCDABCDABDE的第1个字符B与模式串ABCDABD的第1个字符A进行比较。因为B与A不匹配,所以模式串后移1位。 - 然后,尝试匹配主串的第2个字符与模式串的第1个字符,匹配失败,模式串继续后移。
- ……。就这样,直到与模式串的第一个字符相同为止,本例中为
txt的第4个字符A。 - 匹配成功后依次匹配主串和模式串的下一个字符,直到模式串匹配完成或者中途匹配失败。
- ……。就这样,直到匹配到主串第11个字符
- 然后,将模式串后移1位,重新开始以上流程循环匹配。
一个简单的伪代码实现如下:
|
|
在暴力算法中,如果出现不匹配字符,同时回退txt和pat的指针,嵌套for循环,时间复杂度$O(MN)$,空间复杂度$O(1)$。
最长公共前后缀
暴力算法效率低的根本原因是每次匹配失败都会完全回退pat指针,以致进行了大量重复的匹配,因此根据动态规划的思想3我们可以设置一个数组存放匹配记录,在每次回溯模式串指针时根据数组调整回溯的位置(而非回到起点),以空间换时间的方式提高算法效率,这样的一个数组就是最长公共前后缀数组(Comfix数组),也称next数组、部分匹配表、前缀表。那什么是最长公共前后缀呢?
给定一个长度为n的字符串S,其最长公共前后缀被定义为一个长度为n的数组Comfix。其中Comfix[i]的定义是:
- 如果子串
S[0:i]有一对相等的真前缀与真后缀:S[0:k-1]==S[i-(k-1):i],那么Comfix[i]就是这个相等的真前缀(真后缀)的长度,也就是Comfix[i]=k。 - 如果不止有一对真前缀与真后缀相等,那么
Comfix[i]就是其中最长的那一对的长度。 - 如果没有相等的,那么
Comfix[i]=0,特别的Comfix[0]=0。
对于本例的pat模式串ABCDABD来说:
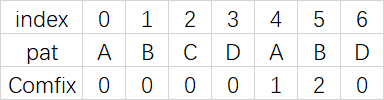
Comfix[0]=0,因为A的前缀和后缀都为空集,共有元素的长度为0。Comfix[1]=0,因为AB的前缀为[A],后缀为[B],共有元素的长度为0。Comfix[2]=0,ABC的前缀为[A,AB],后缀为[BC,C],共有元素的长度0。Comfix[3]=0,ABCD的前缀为[A,AB,ABC],后缀为[BCD,CD,D],共有元素的长度为0。Comfix[4]=1,ABCDA的前缀为[A,AB,ABC,ABCD],后缀为[BCDA,CDA,DA,A],共有元素为A,长度为1。Comfix[5]=1,ABCDAB的前缀为[A,AB,ABC,ABCD,ABCDA],后缀为[BCDAB,CDAB,DAB,AB,B],共有元素为AB,长度为2。Comfix[6]=1,ABCDABD的前缀为[A,AB,ABC,ABCD,ABCDA,ABCDAB],后缀为[BCDABD,CDABD,DABD,ABD,BD,D],共有元素的长度为0。
最长公共前后缀应用
在暴力算法中,当我们遇到不匹配时,会直接将模式串后移一位并从头匹配:

在引入最长公共前后缀后,我们发现,当遇到不匹配时完全可以将与模式串已匹配的(最长)真后缀相等的真前缀直接移到真后缀这里:

在上图中,我们匹配到索引10的字符时发现不匹配,查看已匹配的模式串ABCDAB中有一个长度为2的最长公共前后缀AB,于是直接将公共前缀的AB移到公共后缀的AB位置处4,然后在继续从索引处10开始匹配。将过程从数学上来表示就是,每次发现不匹配时,就将模式串向右移动 已匹配的模式串长度-已匹配的模式串最长公共前后缀长度 个单位。
代码实现
计算最长公共前后缀数组
KMP算法最难理解的部分就是最长公共前后缀数组Comfix的计算,现以模式串ABCDABD为例说明详细计算过程:

- 初始化
Comfix[0]=0,j=0,从索引i=1开始遍历模式串。 - 当
i=1,2,3时,j=0,pat[i]!=pat[j],所以Comfix[1,2,3]=j=0。 - 当
i=4时,j=0,pat[i]==pat[j],先使j=j+1,所以Comfix[4]=j=1。 - 当
i=5时,j=1,pat[i]==pat[j],先使j=j+1,所以Comfix[5]=j=2。 - 当
i=6时,j=2,pat[i]!=pat[j],需要回溯:- 使
j=j-1,此时i=6,j=1,pat[i]!=pat[j] - 使
j=j-1,此时i=6,j=0,pat[i]!=pat[j],Comfix[6]=j=0。
- 使
注意:
- 这里应当明白,
Comfix数组中的每个元素的值都与上一个元素的值相关,且Comfix[i+1]最多只比Comfix[i]大1;j始终指向最长前缀的末端,所以j本身亦可代表所指向最长前缀的长度。- 网上很多实现中Comfix数组是
Comfix[0]=-1,与本例中区别只是边界判断方法不同,并无优劣。
上述流程的Golang实现代码为5:
|
|
字符串查找代码实现
具体的字符串查找方式就是调用Comfix数组进行匹配,其过程与上文的最长公共前后缀应用描述一致,其大致流程如下:
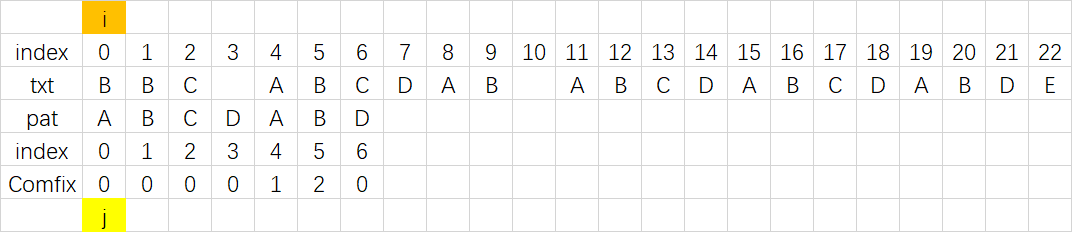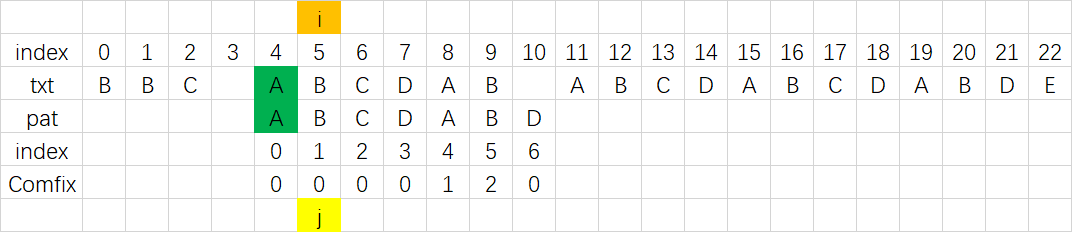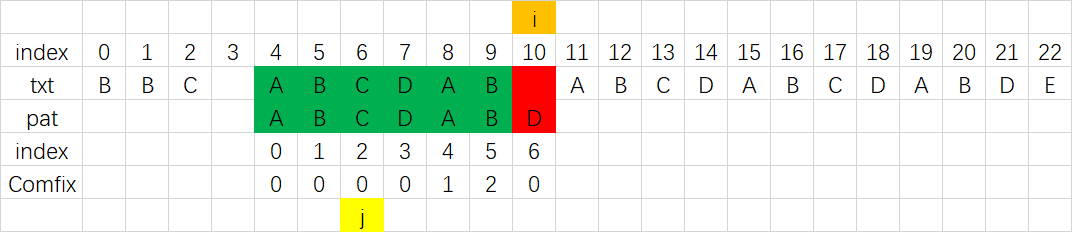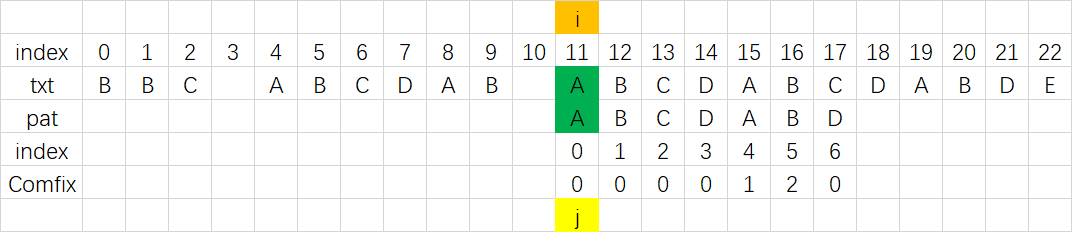
|
|
全部Golang测试代码为:
|
|
参考
-
StudyingFather. 前缀函数与 KMP 算法. OI Wiki. [2021/12/29] ↩︎
-
阮一峰. 字符串匹配的KMP算法. 阮一峰的网络日志. [2013-05-01] ↩︎
-
labuladong. 如何更好地理解和掌握 KMP 算法?. 知乎. [2020-07-15] ↩︎
-
天勤率辉. 「天勤公开课」KMP算法易懂版. BiliBili. [2019-04-20] ↩︎
-
代码随想录. 实现 strStr(). 代码随想录. [2022-03-09] ↩︎